媺撪憡娭學悢
椺戣
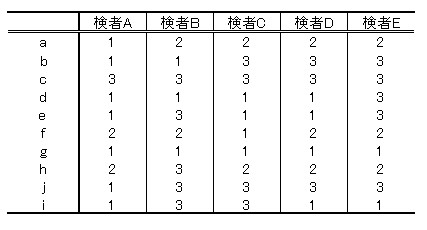
丂忋偺僨乕僞偼丆偁傞昡壙朄乮3抜奒昡壙乯傪梡偄偰丆旐専幰10恖乮a乣j乯傪懳徾偵丆専幰A乣E偺5恖偱昡壙偟偰敾掕偟偨寢壥偺僨乕僞偱偡丏
椺偊偽専幰A偼a傪1偲敾掕偟偰偄傑偡丏僨乕僞偼偐側傜偢偙偺宍幃偱擖椡偟偰偔偩偝偄丏
丂夝愅偟偨偄偺偼丆嘆偁傞昡壙朄傪梡偄偰丆旐専幰a乣i傪専幰A乣E偵傛偭偰昡壙偟丆嵞尰惈乮怣棅惈乯偼偁傞偐偳偆偐傪抦傝偨偄丏偲偟傑偡丏
丂暿偵丆専幰A乣E傪専幰A偺傒偲偟丆嘇偁傞昡壙朄傪梡偄偰丆旐専幰a乣i傪専幰A偵傛偭偰偔傝曉偟5夞昡壙偟丆嵞尰惈乮怣棅惈乯
偼偁傞偐偳偆偐傪抦傝偨偄丏偱傕傛偄偱偡丏
嘆忋昞傪EXCEL偵擖椡偟偰丆僐僺乕偟傑偡乮儔儀儖[暥帤]晹暘偼僐僺乕偣偢僨乕僞悢抣晹暘偺傒乯丏
嘇R傪奐偄偰僐儅儞僪儔僀儞愭摢亜偐傜乽x<-excel.w(5)乿偲擖椡偟傑偡丏x偼R忋偱偺僨乕僞柤乮偲傝偁偊偢偙偺傑傑擖椡偟偰偔偩偝偄乯丆
乮5乯偼丆5楍偺僨乕僞偲偄偆堄枴偱偡丏傕偟帺暘偺僨乕僞偑7楍偱偁傟偽丆乽x<-excel.w(7)乿偲擖椡偟傑偡丏
嘊擖椡偑姰椆偟偨傜丆傑偢偼ENTER僉乕傪墴偟傑偡丏
嘋偦偺屻丆僐儅儞僪儔僀儞愭摢亜偐傜
亜ICC.CI(x丆95)丂
偲擖椡偟丆ENTER偟傑偡丏乭95乭偼95亾怣棅嬫娫偺堄枴偱偡丏99偲偡傞偙偲偱丆99亾怣棅嬫娫傕巜掕偱偒傑偡丏
> ICC.CI(x,95)
丂丂丂丂丂丂丂丂estimate丂丂lower bound-95%丂丂upper bound-95%
ICC(1,1) 丂0.2668539 丂 0.02914107 丂 0.6399035
ICC(1, 5 ) 0.6453804丂 0.13049438 丂 0.8988383
ICC(2,1) 丂0.2800000 丂 0.05134072 丂 0.6433879
ICC(2, 5 ) 0.6603774 丂 0.21296788 丂 0.9002079
ICC(3,1) 丂0.3075758 丂 0.05525117 丂 0.6742791
ICC(3, 5 ) 0.6895380 丂 0.22625289 丂 0.9118987
丂慡偰偺ICC偲丆怣棅嬫娫偑弌椡偝傟傑偡丏
丂忋弎偺嘆偺応崌偼丆ICC乮1丆1乯傪嶲徠偟傑偡丏estimate偑ICC乮1丆1乯偺寢壥偱偡丏嘇偺応崌偼丆ICC乮俀丆1乯傪嶲徠偟傑偡丏
estimate偑ICC乮2丆1乯偺寢壥偱偡丏ICC乮3丆1乯偼偝偟偁偨傝婥偵偟側偄偱偔偩偝偄丏嵞尰惈偑崅偄偲偼丆ICC偑丆偍傛偦0.7埲忋偺偲偒偱偡丏
斖埻惂栺惈偺栤戣
丂ICC偼旐専幰偺僨乕僞偺偽傜偮偒偑戝偒偄偲偒丆崅偔側傞惈幙傪帩偭偰偄傑偡丏偮傑傝丆寬峃側20嵨戙偺埇椡傪懳徾偲偟偰ICC傪媮傔傞偲偒傛傝傕丆
寬峃側20嵨戙偐傜70嵨戙傑偱偺埇椡傪懳徾偲偟偰ICC傪媮傔傞曽偑崅偔側傝傑偡丏懳徾幰偺擭楊偵暆偑偁傟偽抣偼偽傜偮偒傑偡偺偱丆ICC傕崅偔側傝傑偡丏
丂偦偙偱丆SEM傪媮傔丆偙傟傪斾妑偡傞懳嶔朄偑偁傝傑偡丏
丂
丂椺偊偽忋偺椺偺丆専幰A乣C偺僨乕僞偲専幰D乣E偺僨乕僞偱斖埻惂栺惈偺栤戣偑側偄偐挷傋偨偄偲偟傑偡丏SEM偼
>sem2乮僨乕僞柤乯
偱媮傔傜傟傑偡丏
嘆EXCEL偺専幰A乣C偺僨乕僞傪僐僺乕偟丆R偱僐儅儞僪儔僀儞愭摢亜偐傜乽x<-excel.w(3)乿偲擖椡偟傑偡丏偙傟偱x偲偄偆僨乕僞偵専幰A乣C偺僨乕僞偑擖偭偨偙偲偵側傝傑偡丏
嘇摨條偵丆EXCEL偺専幰D乣E偺僨乕僞傪僐僺乕偟丆R偱僐儅儞僪儔僀儞愭摢亜偐傜乽y<-excel.w(2)乿偲擖椡偟傑偡丏偙傟偱y偲偄偆僨乕僞偵専幰D乣E偺僨乕僞偑擖偭偨偙偲偵側傝傑偡丏
嘊傑偢R偱丆ICC傪媮傔傑偡丏娭悢偼ICC.CI乮倶丆95乯偲ICC.CI乮y丆95乯偱偡丏
> ICC.CI(x,95)
丂丂丂丂丂丂丂丂丂丂丂estimate 丂lower bound-95% upper bound-95%
ICC(1,1) 丂丂0.2297297 丂-0.12444906 丂丂丂丂0.6647228
ICC(1, 3 ) 丂0.4722222 丂-0.49706599 丂丂丂丂0.8560700
ICC(2,1)丂丂 0.2660944 丂-0.05116034丂丂丂丂 0.6725701
ICC(2, 3 )丂 0.5210084 丂-0.17097532丂丂丂丂 0.8603794
ICC(3,1) 丂丂0.3100000 丂-0.07083631丂丂丂丂 0.7193753
ICC(3, 3 ) 丂0.5740741 丂-0.24758495丂丂丂丂 0.8849309
> ICC.CI(y,95)
丂丂丂丂丂丂丂丂estimate 丂丂lower bound-95% upper bound-95%
ICC(1,1) 丂丂0.4626866 丂丂-0.16254582丂丂丂 0.8303722
ICC(1, 2 ) 丂0.6326531丂丂 -0.38819036丂丂丂 0.9073261
ICC(2,1) 丂丂0.4782609丂丂 -0.09528997 丂丂丂0.8322453
ICC(2, 2 ) 丂0.6470588 丂丂-0.21065306 丂丂丂0.9084431
ICC(3,1) 丂丂0.5076923丂丂 -0.13592367 丂丂丂0.8499581
ICC(3, 2 ) 丂0.6734694 丂丂-0.31461034丂丂丂 0.9188944
丂ICC乮2丆1乯偼y丆偡側傢偪専幰D乣E偺曽偑怣棅惈偼崅偄偲敾抐偟傑偡丏
偟偐偟丆斖埻惂栺惈偺栤戣偑偁傞偺偱SEM傪媮傔偰専摙偟偰偐傜丆ICC偑崅偄掅偄偲敾抐偟側偗傟偽側傝傑偣傫丏
SEM偼丆旐専幰偺僨乕僞偦偺傕偺偺戝彫偵塭嬁偝傟偢丆弮悎偵應掕娫偺岆嵎傪昞偟傑偡丏偦偟偰丆SEM偼彫偝偄傎偳丆僨乕僞偺僶儔僣僉偑彮側偄偙偲偵側傝傑偡丏
丂sem2(x)丆sem2(y)偲擖椡偡傞偲丆埲壓偑弌椡偝傟傑偡丏
> sem2(x)
丂丂SEM丂丂 lower bound-95% 丂upper bound-95% 丂lower bound-99% 丂upper bound-99%
0.7149204 丂0.5402029 丂丂丂丂丂丂丂1.0572418丂丂丂 丂0.4975959 丂丂丂丂丂1.2118257
> sem2(y)
丂丂SEM 丂丂 lower bound-95% 丂upper bound-95% 丂lower bound-99% 丂upper bound-99%
0.5962848 丂0.4101457 丂丂丂丂丂丂丂1.0885836 丂丂丂丂0.3683130 丂丂丂丂丂1.3581059
丂SEM偼x偑0.7149204丆y偑0.5962848偱丆x偺曽偑戝偒偔側偭偰偄傑偡丏偮傑傝x偺僨乕僞偺岆嵎偼戝偒偄偙偲偑傢偐傝傑偡丏
丂偙傟偼ICC偑彫偝偄偙偲偲傕娭楢偟傑偡丏SEM偑摨偠偲偄偆偙偲偼岆嵎帺懱偼摨堦側偺偱丆ICC偺抣偑堎側偭偰偄偰傕崅偄掅偄偼媍榑偱偒傑偣傫丏
丂媡偵丆SEM偑桳堄偵戝偒偄彫偝偔丆偐偮ICC偑戝偒偄彫偝偄偲偒偼丆崻嫆傪帩偭偰崅偄掅偄偺媍榑偑弌棃傑偡丏
丂桳堄偵戝偒偄彫偝偄傪敾抐偡傞偵偼怣棅嬫娫偑栶棫偪傑偡丏
丂偙偺椺偱偼丆x偺SEM偺95亾怣棅嬫娫偼[0.5402029乣1.0572418]偱偡丏y偺SEM偺95亾怣棅嬫娫偼[0.4101457乣1.0885836 ]偱偡丏偙傟傜偺怣棅嬫娫偼僆乕僶乕儔僢僾偟偰偄傞偺偱ICC偺抣傪扨弮偵斾妑偡傟偽崅偄掅偄偲側傝傑偡偑丆
桳堄偵ICC偑崅偄掅偄偲偼偄偊側偄偙偲偵側傝傑偡丏
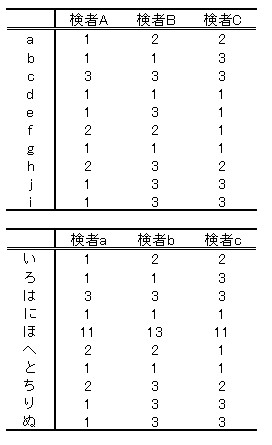
偆偊偺2偮偺昞偱丆嵍偺昞偲塃偺昞偱偼丆嵍昞偺旐専幰e偲丆塃昞偺旐専幰傎偺抣偑堎側傞偩偗偱偡丏
乽e乿偼乽1丆3丆1乿偱乽傎乿偼乽11丆13丆11乿偱偡丏
傎亖e+10偲偄偆娭學偵偁傝丆僨乕僞偺僶儔僣僉帺懱偼嵎偑偁傝傑偣傫乮偦傟偧傟専幰偺嵎偼丆2偲-2偱摨堦乯丏
扨偵掕悢10偩偗崅偔側偭偰偄傞偲偄偆偙偲偱偡丏ICC傪媮傔偰傒傞偲丆嵍偼ICC(2,1)亖0.266丆塃偼ICC(2,1)亖0.939偱偡丏
乽塃昞偺怣棅惈偼崅偄乿偲偄偆偙偲偵側傝傑偡丏偟偐偟丆傎亖e+10偲側偭偰偄傞偩偗偱丆僨乕僞偺僶儔僣僉帺懱偼嵎偑偁傝傑偣傫乮偦傟偧傟専幰偺嵎偼丆2偲-2偱摨堦乯丏
偦偙偱SEM傪媮傔傞偲丆椉幰偲傕SEM亖0.7149204偲摨堦偵側傝傑偡丏