統計解析Q&A-相関と回帰分析-
| Q1:相関と回帰の違いは何か?2つの変数の比例関係を見る点では相関も回帰分析も変わりないように思われるが…。 |
A
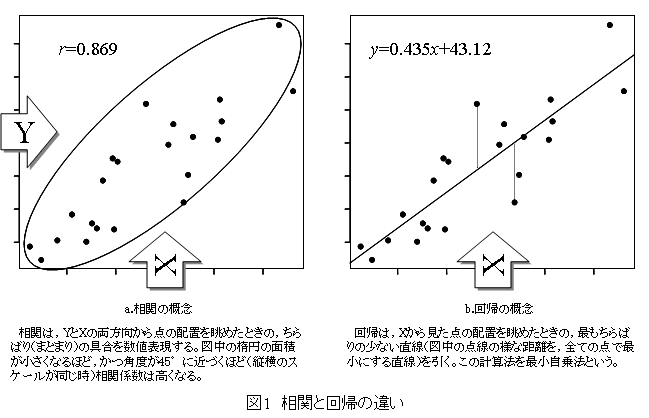
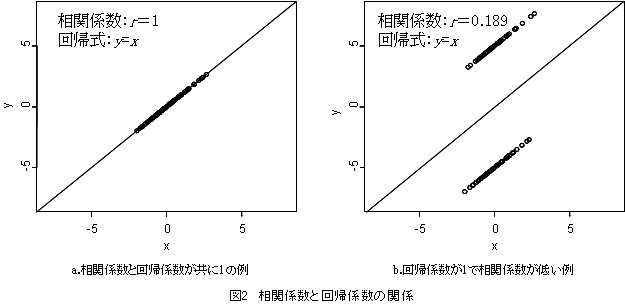
1:2変数がどれくらい散らばっているかを表すのが相関[係数]である(図1a)。一方の変数から他方の変数を予測するために最も都合の良い直線を引くのが回帰[分析]である(図1b)。これらの目的は根本的に異なり,Altman1)も両者を同時に求めることはあり得ないと述べている。従って,事前に「比例関係」とは何かを明確に定義づけて使い分けるのがポイントとなろう。同一のデータであっても,相関係数と回帰係数が大きく異なることは意外に多い。1つの例を挙げよう。図2aは相関係数と回帰係数が,ともに1の直線関係にある例である。さて図2bは図2aと比べて回帰式が変化せず,相関係数のみが低くなった例である。回帰係数はyに対し,x方向からみて誤差が最小となるような直線を引くから1になるのである。もちろん図2bのように極端に散らばっていなくても,y=xの直線を中心にデータが上下に均等に散らばっていれば回帰係数は1に近い値をとる。
| Q2:ブルンストロームステージと歩行速度の相関係数を求めたところ,「ブルンストロームステージは順序尺度であるから,順位相関係数を使った方がよい」という意見があった。順位相関係数とは何か?また,なぜ相関係数ではだめなのか。 |
A
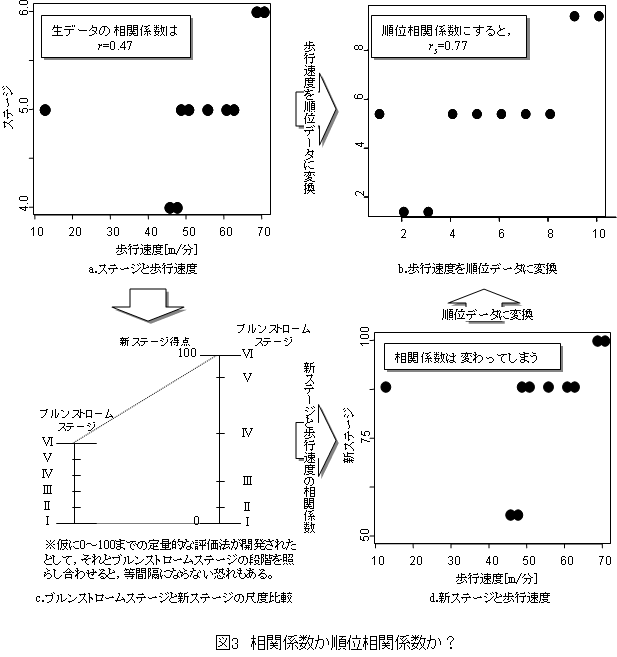
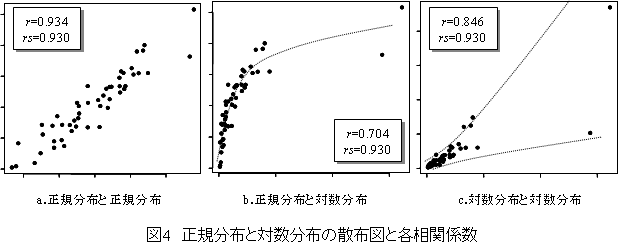
2:一般に“相関係数”とは,“ピアソンの積率相関係数”のことを指す。これは積率相関係数,ピアソンの相関係数と呼ばれることもある。“順位相関係数”とは,通常,スペアマンの順位相関係数のことを意味する。ピアソンの積率相関係数は,データが釣り鐘状に分布する正規分布を仮定するパラメトリック法である。なお,相関係数は“r”と略される。対して順位相関係数は,データの分布が正規分布とは考え難いときに適用となるノンパラメトリック法である。順位相関係数には,スペアマンの順位相関係数の他にケンドールの順位相関係数というものもある。どちらを使うべきか悩むこともあろうが,理論的にも前者を使った方が妥当である。スペアマンの順位相関係数は“スペアマンのρ”とか“rs”と略される。ブルンストロームステージは順序尺度の評価法であり,各段階が等間隔ではない。相関係数と順位相関係数を比べてみると,図3aよりもbの値が大きく異なる。仮に麻痺を0~100の範囲で定量的に表せる新ステージが開発されたとして,ブルンストロームステージと照らし合わせて(図3c)散布図を描くと図3dのようになり,相関係数は異なった値をとるであろう。この新ステージも順位データに変換して順位相関係数を求めれば,再び図3bと同じになる。このように順位相関係数は単位に依存しない相関係数を算出する特徴があり,順序尺度で測られて,かつ正規分布に従わないデータの相関係数を求める際に適した手法となる。参考として,正規分布と対数分布の相関関係を相関係数とスペアマンの順位相関係数で表した(図4)。順位相関係数は分布の形や外れ値に影響を受けず,何れも同じ値を示している。
しかし,順位相関係数は点の大小関係だけを表すので,仮に図4b,cにみられるような外れ値に重要な情報が隠されている場合でも見過ごす危険性がある。
| Q3:相関係数が高ければ2変数の関連性が高いように思われるが,ある人に「検定が有意でなければ『相関が高い』とはいい切れない」と言われた。 |
A
3:相関係数が高いことと係数の検定が有意であることとは独立であると解釈しなければならない。つまり,検定が有意であっても相関が高いときと低いときがある。従って「有意であってかつ相関が高い」ことを言及するためには,以下の条件をクリアする必要がある。①まずは検定結果が有意となる必要がある。しかし,検定で有意となったときは“母相関係数(真の相関係数)が0でない”ことをいっているに過ぎない。つまり,r=0.000…1~r=1(またはr=-0.000…1~r=-1)までの値をとることを証明しただけである。
②次に相関係数の95%(または99%)信頼区間を求め,下限値(正確には値が0に近い方)が一定の基準値を超えているか確認する。“一定の基準値”は理論的に決められていないが,最低でも絶対値がr=0.5(中等度の相関)であることが望ましい。
③上記①②が満たされたなら,求めた相関係数値(標本相関係数)から,相関の程度を比較,評価できる。
| Q4:変数Aと変数Bの相関係数は高く,また検定も有意であった。そこで「AとBの相関関係は強い」と結論づけたいが,専門家に疑似相関の危険性を疑えと指摘された。疑似相関とは何か?またその確認方法は? |
A
4:疑似相関は見かけの相関とも呼ばれ,2つの変数の相関が高いとき,影響の大きい変数がその背後に存在する状態をいう。これだけでは何のことかわかりづらいので,簡単な例を挙げる。例えば,「知能指数と身長は有意でかつ,高い相関関係にあった」という結果を得たとしよう。一般的に考えておかしい気はするが,現実に相関係数は高い。しかし,掘り下げて調べてみると,対象が小学1年生から6年生までの学童児であったことが判明した。実は年齢と知能指数の相関が高かったことと,年齢と身長の相関が高い結果,見かけ上知能指数と身長に有意な相関が見られただけだった。このような現象を疑似相関といい,背後に潜む変数“年齢”を制御変数という。制御変数の探索には統計学の専門性ではなく,解析者の専門性が生かされる。このような場合は,制御変数を年齢として知能指数と身長の偏相関係数を求めるとよい。
| Q5:r=0.24(p<0.05)で有意な場合とr=0.24でも有意とならない場合がある。これはなぜか? |
A
5:相関係数の検定では,差の検定と同様,標本の大きさが大きい(対象者数が多い)とき値が小さくても有意となる。r=0.1のような値でも有意となってしまうことがある。例えば100ないし200例規模の研究で「○○と○○はr=0.24(p<0.05)で有意であった」という記載を見かけるが,これは有意なだけであって相関が高いとはいえない(まさしくA1-3の①の状態)。また,「r=0.42でp<0.001の高い相関関係にあった」という記載も誤りで,確率pがいくら低くても,相関の程度とは関係がないことも知っておかなければならない。結局,A1-3①~③のような手順を踏まえて初めて相関の程度を言及できるのである。| Q6:xとyの回帰式を求めたが,これが実際にどれくらい役立つか知りたい。客観的な指標はないだろうか。 |
A
6:回帰式を述べて相関係数も求め,相関係数が有意であるから,回帰式も有意であるといった勘違いがある。回帰直線式y=a+bxにおいて,yは従属変数(または目的変数),aは切片,bは回帰係数,xは独立変数(または説明変数)と呼ばれる。求めた回帰式がどれくらい役立つかの客観的指標として,bが0か否か,すなわち傾きが0か否かを検定する方法とaが任意の値と異なるかどうかを検定する方法がある(詳細は市原など2)を参照)。当然,この場合も母回帰係数・切片が0であるか否かを検定するに過ぎないので,相関係数の検定と同様,95%(または99%)信頼区間を参考にするべきであろう。また,統計ソフトによっては分散分析の結果や決定係数(R2)が同時に出力される。これは,回帰の当てはまり度を検定するものである。決定係数は0~1の範囲で表され,R2=1は回帰式とデータが完全に一致することを示す。しかし,これらの指標も鵜呑みにすると大きな過ちを冒しかねない。
図5はAnscombe3)の例をもとに筆者が作成したデータである。これらは全てy=0.49x-0.017の回帰式を示す。また,残差も相関係数も決定係数も同一となる。こうなると,回帰式の検定結果や分散分析の結果,そして決定係数を提示したとしても信用できない。このような例では,散布図を提示しない限り区別するのは難しい。何よりも図を提示することの重要性を理解できるであろう。その上で,直線回帰でよいか,外れ値を除外した方がよいかの判断も行うべきである。
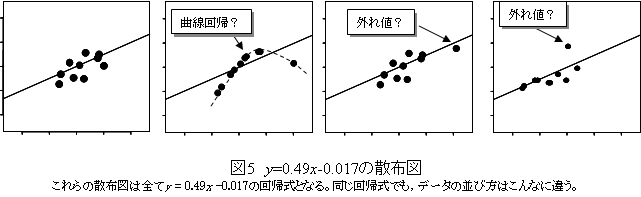
| Q7:膝関節手術後の患者10名を対象に術後期間と膝関節伸展筋力の変化を知りたい。そこで,膝関節術後1週間後,2週間後,3週間後,4週間後のデータをとって,膝関節伸展筋力と術後経過期間の回帰式を求めたが,正しいであろうか。 |
A
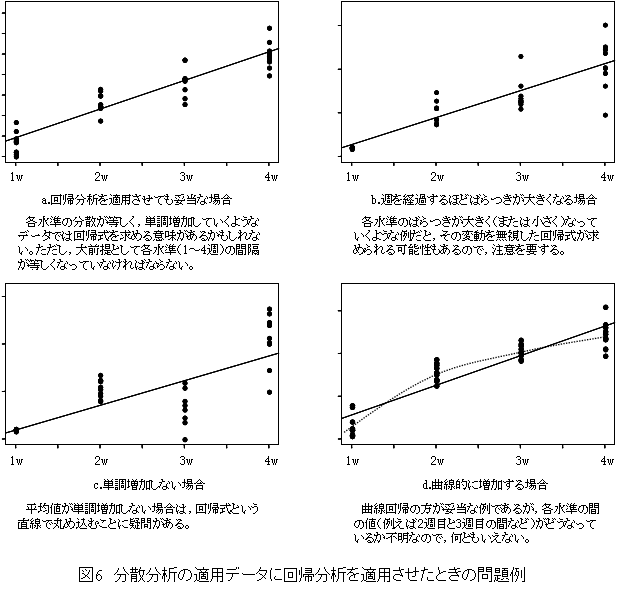
7:これは結論からいうと正しいとはいえない。確かに,回帰分析と分散分析の根本的理論は同一である。しかし,専門的にいえば通常の回帰分析は説明変数が確率変数である線形回帰モデルであるのに対し,分散分析は説明変数が非確率変数である線型モデルである点で違いがある。回帰分析では,説明変数(x)の値は確率の法則に従って変動する。分散分析では,説明変数に相当する変数が水準という形で意図的にとられるから,確率的に変動するとはいえない。質問の例では,解析者が1~4週後の間で1週間おきに意図的に決めてとっている非確率変数であり,解析の目的からしても反復測定による分散分析を適用させるべきである。回帰式を求めるだけでは,意味のある情報を得られない例として図6を見れば理解できる。
文献
1)Altman DG:医学研究における実用統計学(木船義久,他訳).サイエンティスト社,p227-264,1999.
2)市原清志:バイオサイエンスの統計学.南江堂,1990.
3)Anscombe FJ:Graphs in statistical analysis.The American Statistician 27:17-21,1973.